Quickstart¶
This page provides an introduction to how to use Carsus.
Initialize a database¶
Initializing a database is a matter of calling the init_db function.
You must pass to the function a database url. You can also pass
optional keyword arguments to establish various engine options, e.g.
echo=True. init_db creates and returns a session object that is
used to query the database. Let’s initialize a SQLite memory database:
In [1]:
from carsus import init_db
session = init_db("sqlite://")
session.commit()
Initializing the database
Ingesting basic atomic data
Because the database was empty, basic atomic data (atomic numbers, symbols, etc.) was added to it. You should commit the session yourself if you want changes to be persisted to the database! Let’s query the database:
In [2]:
from carsus.model import Atom
q = session.query(Atom).all()
for atom in q[:5]:
print atom
<Atom H, Z=1>
<Atom He, Z=2>
<Atom Li, Z=3>
<Atom Be, Z=4>
<Atom B, Z=5>
In [3]:
session.query(Atom).count()
Out[3]:
118
The figure below illustrates the database schema. Atoms have some
fundamental quantities, like atomic numbers and groups, and quantites
that can depend on a data source. The latter are stored in the
AtomicQuantities table. The AtomicWeights table is a subset
table of AtomicQuantities and it represents a specific type of
quantities - atomic weights. Although there is only one quantity type in
this schema, generally there can be many.
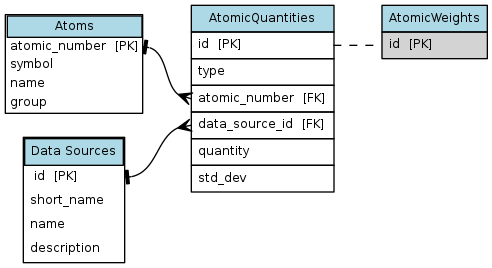
atomic schema
Ingest data¶
To ingest data from a source you need to create an ingestor for that
source. In this example we will ingest atomic weights from the NIST
Atomic Weight and Isotopic
Compositions database. After
you have created the ingestor, you need to call two methods:
download and ingest. The first one will download data from the
source and the second one will ingest it into the database. You must
pass a Session object to the ingest method! You should commit the
session after the data have been ingested.
In [4]:
from carsus.io.nist import NISTWeightsCompIngester
ingester = NISTWeightsCompIngester()
ingester.download()
ingester.ingest(session)
session.commit()
Downloading the data from http://physics.nist.gov/cgi-bin/Compositions/stand_alone.pl
Ingesting atomic weights
Query the database¶
Let’s do some queries. To select both atoms and atomic weights we need
to join the Atoms table on the AtomicWeights table. We use
join() to create an explicit JOIN. To specify the ON parameter we
provide the relationship-bound attribute of the Atom class -
Atom.quantities - and then use the of_type() helper method to
narrow the criterion to atomic weights. This query selects the first
five atoms with the values of their atomic weights:
In [5]:
from carsus.model import AtomicWeight, DataSource
session.query(Atom, AtomicWeight).\
join(Atom.quantities.of_type(AtomicWeight)).\
filter(Atom.atomic_number <= 5).all()
Out[5]:
[(<Atom H, Z=1>, <Quantity: atomic_weight, value: 1.007975>),
(<Atom He, Z=2>, <Quantity: atomic_weight, value: 4.002602>),
(<Atom Li, Z=3>, <Quantity: atomic_weight, value: 6.9675>),
(<Atom Be, Z=4>, <Quantity: atomic_weight, value: 9.0121831>),
(<Atom B, Z=5>, <Quantity: atomic_weight, value: 10.8135>)]
Let’s select atoms that have atomic weight less than 15 u. We can do the
query using the .quantity column in a single comparison. Notice that
to interpret .quantity directly at the moment we need to use
.value accessor:
In [6]:
from astropy import units as u
session.query(Atom.atomic_number,
AtomicWeight.quantity.value).\
join(Atom.quantities.of_type(AtomicWeight)).\
filter(AtomicWeight.quantity < 15*u.u).all()
Out[6]:
[(1, 1.007975),
(2, 4.002602),
(3, 6.967499999999999),
(4, 9.0121831),
(5, 10.8135),
(6, 12.0106),
(7, 14.006855)]
Output dataframes¶
Lets put out a table with z, weight in solar masses, z**2 + 5:
In [7]:
# First we need to write a query
# Unit conversion is done on the DB side!
q = session.query(Atom.atomic_number.label("z"),
AtomicWeight.quantity.to(u.solMass).value.label("weight_solMass")).\
join(Atom.quantities.of_type(AtomicWeight))
# Then we use pandas to read the query into a DataFrame
from pandas import read_sql_query
df = read_sql_query(q.selectable, session.bind)
# Once we have the data we can compute things
df["z**2+5"] = df["z"]**2 + 5
print df.head(5)
z weight_solMass z**2+5
0 1 8.414768e-58 6
1 2 3.341449e-57 9
2 3 5.816602e-57 14
3 4 7.523543e-57 21
4 5 9.027316e-57 30